
This blog post will present the modern EDR landscape, pitfalls faced during implementation, and best practices. We’ll offer a clear roadmap for rolling out an enterprise-grade solution, plus discuss modern, AI-based solutions that complement your EDR program by reducing noise, accelerating response, and integrating seamlessly with your toolkit.
Understanding EDR in the modern enterprise
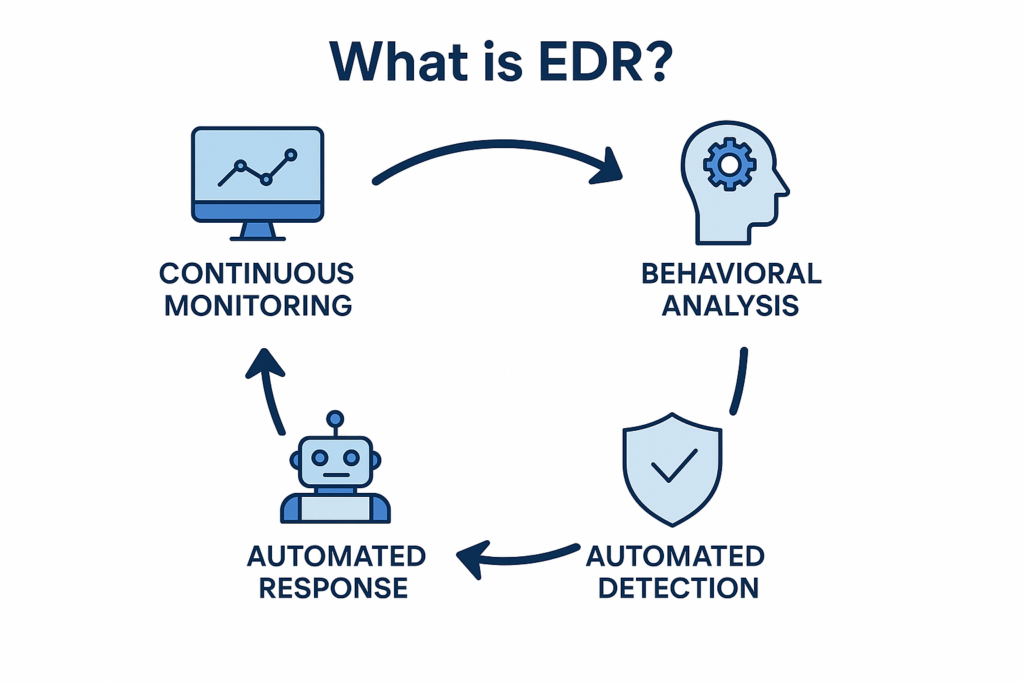
EDR platforms combine continuous telemetry collection with behavioral analytics and automated response capabilities.
EDR’s real-time rule sets and AI-driven classifiers automatically correlate events across hosts to surface multi-stage campaigns. The platform can even execute containment playbooks without any manual intervention to isolate hosts or kill malicious processes.
Where traditional antivirus relies on signature matching and next-gen antivirus (NGAV) layers in some heuristics, modern EDR applies adaptive analytics across your entire fleet—surfacing threats that would otherwise slip through.
Key challenges in EDR implementation
Even with a clear understanding, real-world EDR deployments can trip you up. Let’s break down the major pain points you’ll encounter—and why they matter.
Alert overload and false positives
Before you tackle fine-tuning and expansion, you’ll face an avalanche of alerts that can drown out legitimate threats.
SOCs routinely see 24,000 to 134,000 alerts daily, yet only 0.01% correspond to actual attacks. Some 64% of teams report being overwhelmed by false positives, leading to desensitization and missed detections.
Resource and operational constraints
Scaling EDR often runs headlong into limited resources and complex upkeep demands. Given the alert volumes above, tuning can consume weeks of full-time effort.
Deploying and updating agents across thousands of endpoints—often in air-gapped or remote sites—also adds complexity and delay.
Integration complexities
Even the best detection data is meaningless if it can’t flow seamlessly into your broader security workflows.
Data silos are a real concern. Some 75% of organizations detect breaches on endpoints before external notification—but fail to integrate that context into SIEM/SOAR for faster cross-domain hunts.
You’ll also encounter connector gaps. These require custom parsers and normalization rules to merge EDR logs, network IDS alerts, cloud events, and identity system data into a unified incident picture.
Policy and deployment pitfalls
Missteps in deployment and policy can leave critical blind spots, undermining your entire EDR strategy.
Exception sprawl is also an issue. This is when teams bulk-allowlist critical processes to curb false positives, only to inadvertently blind their EDR to stealthy attacks.
Also, deploying agents unevenly across OS versions or device types leaves coverage gaps for attackers to exploit.
State-of-the-art best practices for EDR
To overcome the above challenges, you need a structured, staged approach grounded in automation, data-driven tuning, and continuous improvement.
Pilot testing and gradual rollout
Start small and learn fast to build confidence before you enforce at scale. Next, enable “detect-only” mode to capture telemetry and validate alerts without impacting workflows.
Remember: Iterative refinement is key. Adjust rule priorities, allowlist known good software, and calibrate thresholds based on real-world noise.
Fine-tuning to reduce false positives
Precision tuning is the key to cutting false positives without sacrificing visibility. This entails behavior-based calibration, where machine-learning models learn from your unique environment—for example, distinguishing inventory scripts from malicious execution.
Maintaining strict change management is also essential. Make sure to require justification for each new exception and track its expiration date.
Automation & centralized management
Automation liberates your analysts to focus on actual threats instead of repetitive triage.
AI-driven triage allows for grouping alerts by attack chain stages and assigning risk scores. Self-service dashboards are a particular boon, providing SOC managers with real-time metrics on MTTR, alert volume, and agent health.
Integration with broader threat intelligence
Threat intelligence only delivers true value when you can integrate it with your endpoint telemetry and swiftly act on the insights it provides. How can you do this?
Feed EDR telemetry into your SIEM/SOAR platform with proper field mappings to enrich alerts with user context, asset value, and historical incident data. As to external threat feeds, make sure to map indicators of compromise (IOCs) from threat intel sources into your EDR to proactively hunt for known bad hashes, IPs, or domains.
Lastly, correlate endpoint events with network IDS/IPS logs for effective cross-domain analytics that can identify multi-vector campaigns.
Regular auditing and patch management
Continuous validation ensures your defenses keep pace with emerging vulnerabilities. This means endpoint audits, for one. Schedule periodic reviews of agent deployment health, policy compliance, and orphaned exceptions.
Patch automation is also critical to ensure your EDR agent and OS patch cycles run in tandem—missing a critical OS patch can undermine your defenses.
And, of course, train, train, train. Tabletop exercises for teams to validate detection logic and response playbooks under real-world scenarios are a must.
EDR deployment 4-step roadmap
Now that you know about EDR best practices, what’s the best way to operationalize them? A clear, phased roadmap, outlined below, is the way to go.
1. Preparation and assessment
A critical risk assessment should cover everything from your catalog asset value and level of data sensitivity to threat vectors—e.g., phishing attempts, insider misuse, and zero-day exploits—that your organization faces.
Next, take an inventory of all endpoints: OS versions, hardware types, and existing security agents. You’ll also have to define KPIs, like your target mean time to detect (MTTD), acceptable mean time to respond (MTTR), and a maximum alert noise ratio (false positives as a percentage of total alerts).
2. Solution selection
When evaluating vendors, use a vendor-agnostic checklist:
| Criterion | Description |
| Scalability | Can it handle >10,000 endpoints without performance degradation? |
| Integration ease | Does it support your SIEM, SOAR, cloud, and network security tools out of the box? |
| Automation capabilities | Is there scalable AI-driven triage that can automatically process unlimited alerts, escalate only true positives, and offer one-click or fully automated response actions? |
| Analytics & reporting | Does the console provide customizable dashboards and drill-down capabilities for forensic analysis? |
| Telemetry | Can you export raw logs to your data lake or SIEM without proprietary lock-in? |
| Cost structure | Is pricing per endpoint, per event, or a flat subscription? |
Be sure to test leading solutions such as CrowdStrike EDR, SentinelOne EDR, Microsoft Defender for Endpoint, and VMware Carbon Black through proof-of-concepts.
3. Deployment phase
It’s time to deploy! Start with a detect-only rollout by installing agents on roughly 10% to 20% of your endpoints in monitoring mode, then assess resource utilization, network impact, and alert volume.
When it comes to policy configuration, define global policies that enforce baseline security settings across your entire fleet. Meanwhile, scoped policies should target specific groups—like engineering—so you can safely enable custom development tools without weakening overall security.
Also, map detections to the proper response by crafting playbooks that automatically contain high-severity alerts while escalating lower-severity incidents for analyst review.
4. Post-deployment management
Once you’ve deployed your endpoint detection and response platform, the work’s not over. Keeping an eye on everything and maintaining proper documentation is critical.
You’ll also have to regularly review false positives with your threat intel and tuning teams, feeding insights into detection models.
And don’t forget to continuously update your runbooks, escalation paths, and playbooks to keep pace with evolving threats and operational changes. Holding quarterly drills will validate team readiness, uncover blind spots, and sharpen response procedures.
Despite all the above and your best efforts to optimize your EDR practice, there are so many other security use cases and corresponding detection tools, that your SOC team might still be experiencing alert fatigue and missing the signals in the haystack of false positives. That’s where Radiant steps in.
Radiant Security’s adaptive AI SOC platform advantage
Radiant ingests and triages any alert type, leveraging your telemetry data so only true positives are escalated to incidents. Integrated response actions can be reviewed and executed by your human analysts in a click. Once confidence has been established, remediation can be fully automated.
Let’s explore Radiant’s offering some more.
Automatic triage and response
Radiant’s platform begins by automatically triaging every known and unknown security alert—no months of training or static rulebooks are required. Its AI dynamically constructs customized triage logic per alert, correlating across endpoint, network, cloud, identity, and threat-intel feeds to pinpoint actual threats with complete visibility.
When Radiant’s AI surfaces a genuine incident, it generates dynamic response plans on the fly—no pre-defined playbook templates.
Unlimited and on-demand data retention
Radiant can also free up the security budget allocated to expensive SIEMs and eliminate lock-in by leveraging customers’ own cloud archive storage. Coupled with Radiant’s modern logging architecture, you can affordably enjoy unlimited data storage and retention with rapid querying and visualization.
Radiant’s open architecture plugs into your existing stack, whether you’re running CrowdStrike EDR, SentinelOne, Microsoft Defender for Endpoint, SIEM, SOAR, or any cloud and network feeds. It lets you store every event in an integrated data lake for rapid querying, leverage over 100 pre-built connectors out of the box, and export raw telemetry on demand for custom analytics or long-term compliance.
Conclusion
Implementing a robust EDR security program is a complex endeavor, but with a structured roadmap, data-driven tuning, and AI-powered automation, you can transform endpoint telemetry into proactive defense.
You’ve learned how to pilot, tune, automate, and scale your EDR deployment—and why modern SOC platforms like Radiant Security’s adaptive AI SOC are critical for staying ahead of emerging threats.
Ready to take your endpoint detection and response strategy to the next level?
Book a demo with Radiant Security to see firsthand how AI-driven triage and one-click response can revolutionize your SOC.





